
Resilience in the Cyber Era
In late 2011, I entered into a project with The Economist Intelligence Unit to write a white paper, to be sponsored by the global consultancy Booz Allen Hamilton. The project’s working title, when it was assigned to me, was “Cyber Strength: The Future of Global Power.” My argument was that nothing about the title, or even the outline as it was handed to me, suggested a thing that the reader would be interested in attaining. It’s hard to know whether the topic here was about geopolitics or steampunk fantasy. I suggested the topic shift to something worth having, a kind of goal. My topic keyword stuck: resilience.
What follows below is the supplemental article for the white paper as it originally appeared on the EIU website, followed by the EIU’s own snapshot of the white paper as it was originally published. You’ll actually see some of the inspiration for the types of charts I would use later in constructing formal content strategies, particularly from Prof. Sterbenz.

The science of resilience aims to determine which variables an organization should pay attention to, and to what degree, in order to maintain a data center that resists failures, tolerates faults, and provides continuity of service to its customers. In February 2011, the European Network and Information Security Agency (ENISA) issued a report on its efforts to develop a framework for data network resilience for EU government services — a framework that would then be the model for data centers throughout Europe.
To ENISA’s surprise, the various stakeholders’ definitions of resilience itself didn’t agree with one another, not even closely. “Resilience was not considered to be a well-defined term and depending on the context, it encompassed several interpretations and viewpoints,” the ENISA report concluded. “Additionally, there was consensus on the fact that information sharing and sources of consolidated information on resilience metrics were not readily available. These challenges were recognized as serious obstacles towards the adoption of resilience metrics.”
The Resilience Formula
In search for a common framework that everyone could agree upon, the Agency discovered a concept being implemented in the US — specifically, at the University of Kansas. There, Professor James P. G. Sterbenz, his colleagues, and students had developed an architecture called ResiliNets. It utilizes a six-point strategy for assessing and attaining resilience, along with a charting mechanism that can be adapted to any organization.
As Professor Sterbenz explained, resilience under the ResiliNets system is a cost/benefit tradeoff. “The more resources you’re willing to devote, the more resilient your system is going to be,” he says. The perfectly fault-resistent network may be unattainable. So an organization needs to determine the extent of tolerance their network can withstand, and develop policies and procedures to respond fully to events within that tolerance level. “In the extreme, the most resilient network possible is a full mesh,” he says. “That is, every pair of nodes and every pair of routers has a link between them. That is absurdly expensive, so that’s not cost-effective. So organizations have to make a tradeoff.”

Figure 1. The ResiliNets strategy formula envisioned as rotating, interdependent cycles. From the University of Kansas ResiliNets strategy, used by permission of Prof. James P.G. Sterbenz.
The ResiliNets formula, D2R2 + DR, stands for: Defend against threats and challenges to normal operation, both actively with people and passively with software and controls; Detect when an adverse event has occurred; Remediate the effects of the event in order to minimize its impact — Professor Sterbenz described a concept called graceful degradation, as a reasonable alternative to “crashing”; Recover to normal operations; then Diagnose the root cause of the event; and finally Refine future behavior as necessary.

Figure 2. Resilience state space and strategy inner loop. From the University of Kansas ResiliNets strategy, used by permission of Prof. James P.G. Sterbenz.
Once an organization has integrated this formula into its everyday processes, the state of its network at any one time can be plotted on a simple chart, the resilience state space (Figure 2). On the chart, the horizontal axis represents the operational state of the network — what the network administrator sees. The vertical axis represents the level of service that the customer perceives from the network. Prof. Sterbenz classifies both malicious threats and natural events such as power outages and device failures as challenges. When a challenge arises, the state point for the network on this chart will move to the right. The objective for resilience is to keep that point toward the lower right corner as much as possible.
“A resilient service is one that, even as you move to the right, stays low. You stay at ‘unacceptable’ and perhaps ‘impaired’, and hopefully don’t go to ‘unacceptable’ service even as the network degrades,” he explains. As challenges occur, a resilient network will adopt a manageable swing pattern on this chart, like a pendulum in a sand pit.
The Resilience Framework
The strategy conceived by the University of Kansas was intended to apply to networks, systems, devices, interconnects, and routers. Yet it does not take into account the other principal component of every organization’s network; its people. While a recent survey conducted by the Economist Intelligence Unit suggested that executives believe their organizations’ employees to be the least important stakeholder in cyber resilience, the survey also suggested an overall sense of complacency towards cyber threats within organizations, and may explain why employees were not granted due consideration.
Educating employees about cyber security and resilience needs to be a key part of any resilience strategy. This requires making resilience principles less mathematical and more contextual, tangible, teachable. IBM has developed the Business Resiliency Framework (BRF), and its core principle is that the responsibility for resilience cuts across all departments and divisions of an organization equally.

Figure 3. IBM Business Resiliency Framework. [Courtesy IBM]
Many corporations designate individuals within each of its divisions as responsible for security in that division. While that seemed sensible in an earlier era, today’s data networks don’t follow the same structure as yesterday’s organizational charts. Linda Laun, who manages global methods and development tools at IBM’s Business Continuity and Resiliency Services (BCRS) division, explains that her company advises its clients to begin incorporating resilience by designating some centralized governance authority — a “chief resilience officer,” for lack of a better phrase — who coordinates the implementation of a single set of policies among the various silos.
The principal task of such an officer would be risk management. One tool IBM offers for this task is a kind of scatter-plot where businesses chart the distribution of its manageable and unmanageable (for now) risks, using a process IBM calls Business Impact Analysis.
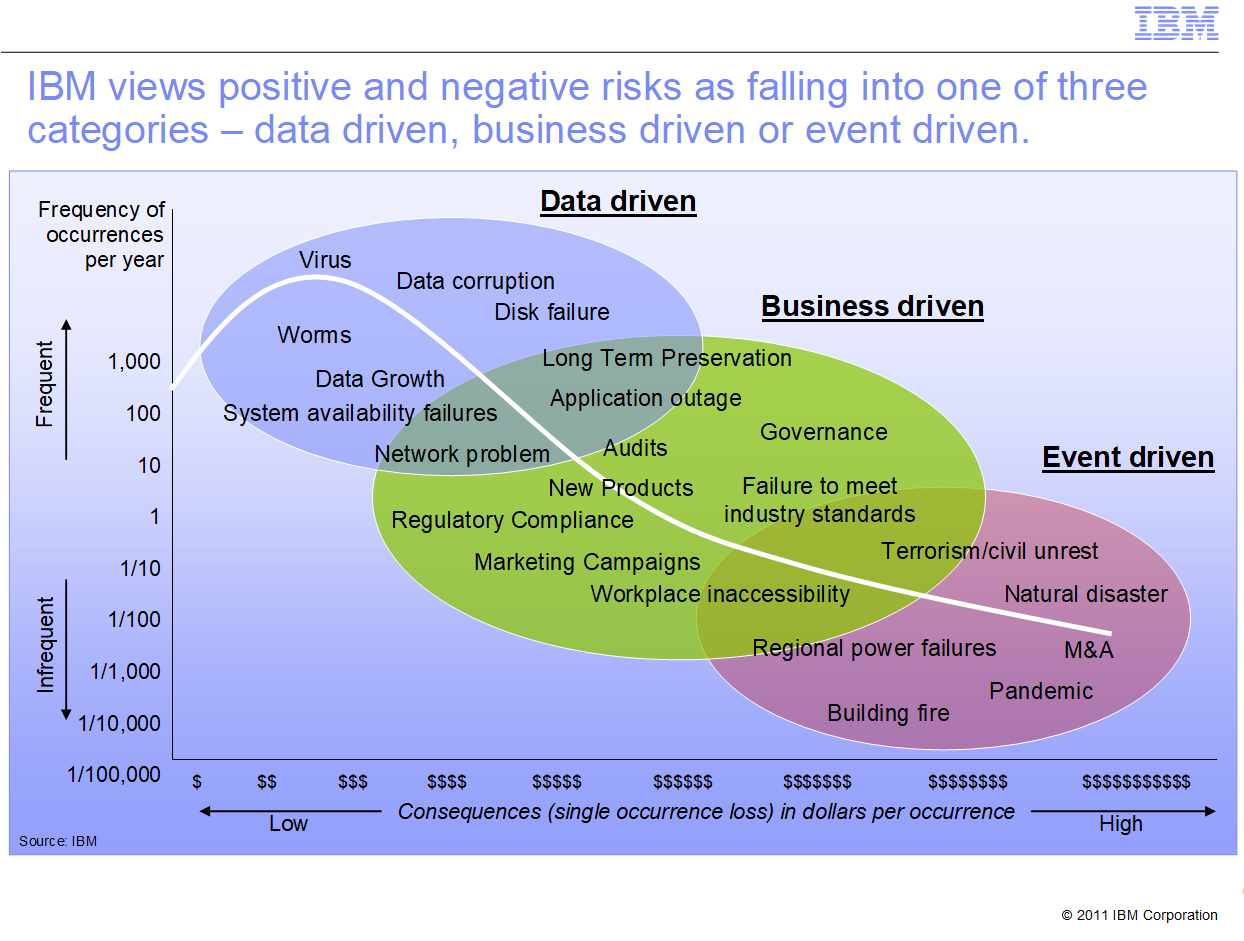
Figure 4. IBM BRF risk calculation plot, which reveals the distribution of resilience challenges based on frequency and severity. [Courtesy IBM]
“BIA helps a company understand ‘what’ and ‘how’ questions when starting a Resilience Program,” explains Ms Laun. Such questions, she says, include “What must I protect?” and, “How long can I be without my critical services and business functions?”
With IBM’s methods, a business can estimate both tangible costs (e.g., financial losses, damages) and intangible costs (e.g., operational capacity, loss of reputation with customers). Having calculations in hand help companies in the mitigation response phase to find support, and even funding.
“Using a standard, proven approach helps to identify the critical business processes and helps substantiate the required investment in the right amount of protection,” says Ms Laun. “A BIA is the most likely step in the lifecycle to be skipped, as companies are reticent to approach the business or afraid it will take too much time. Enlisting the help of professionals helps increase the chances of successful execution and completion of this process.”
“In the extreme, the most resilient network possible is a full mesh. That is, every pair of nodes and every pair of routers has a link between them. That is absurdly expensive, so that’s not cost-effective. So organizations have to make a tradeoff.”
Reality is Somewhere In-Between
The ResiliNets formula and the BRF framework have their roots in two separate aspects of resilience management — respectively, network engineering and human resources. Both are very complex systems; and historically, organizations have had difficulty wrapping their heads around very systematic approaches. Both KU and IBM have worked to implement simpler symbology and easier diagrams. But what security engineers in the field are suggesting is not just to simplify the terms, but to make resilience processes such as risk assessment and risk management practical, simple, everyday affairs rather than annual or semi-annual reviews.
Garry Sidaway, director of security strategy for consulting firm Integralis, points out that motorists do risk assessment every day when they know their lives and safety are at stake. They check their oil and water levels and the positions of their mirrors before leaving the driveway. These are almost non-events now, and Mr Sidaway feels risk assessment for organizations should become non-events as well.
“Businesses are used to making risk decisions. They’re used to saying, ‘This is the market we need to open up, and these are the risks associated with that. This is acceptable, and this is the cost of actually managing that,’” says Mr Sidaway. “Those principles tend to be lost with information security.” There needs to be regular conversations, he adds, among IT professionals on topics such as what would happen if a particular server failed, or if a certain database were to be inaccessible for long periods. They’ll know they’re engaged in risk assessment, but they won’t be approaching them as though they were massive projects.
Len Padilla, senior director of technology for Internet service provider NTT Europe, summarizes the basic concept like this: “At the end of the day, risk management is coming down to balancing the security exposure and the possibility of a compromise, with the cost and probability of it occurring.”